
Wyobraź sobie, że siedzisz zrelaksowany na sofie i po prostu zamawiasz komputer, laptop lub telefon komórkowy, aby wykonać proste czynności, takie jak napisanie listu lub wykonanie kilku poleceń. Czy to możliwe?
Oczywiście, w tym miejscu pojawia się funkcja rozpoznawania głosu.
Zgodnie z definicją jest to proces rozpoznawania mowy ludzkiej i dekodowania jej do postaci tekstowej.
Zasada
Podstawowa zasada rozpoznawanie głosu wiąże się z faktem, że mowa lub słowa wypowiadane przez jakąkolwiek istotę ludzką powodują wibracje powietrza, zwane falami dźwiękowymi. Te ciągłe lub analogowe fale są digitalizowane i przetwarzane, a następnie dekodowane na odpowiednie słowa, a następnie odpowiednie zdania.

Składniki systemu rozpoznawania mowy
Z czego więc składa się podstawowy system rozpoznawania mowy?

- Urządzenie do przechwytywania mowy : Składa się z mikrofonu, który przekształca sygnały fal dźwiękowych na sygnały elektryczne oraz przetwornika analogowo-cyfrowego, który próbkuje i digitalizuje sygnały analogowe w celu uzyskania danych dyskretnych, które komputer może zrozumieć.
- Cyfrowy moduł sygnałowy lub procesor : Przetwarza nieprzetworzony sygnał mowy, taki jak konwersja w dziedzinie częstotliwości, przywracając tylko wymagane informacje itp.
- Wstępnie przetworzone przechowywanie sygnału : Wstępnie przetworzona mowa jest przechowywana w pamięci w celu wykonania dalszego zadania rozpoznawania mowy.
- Odniesienia do wzorców mowy : Komputer lub system składa się z predefiniowanych wzorców mowy lub szablonów, które są już zapisane w pamięci i służą jako odniesienie do dopasowania.
- Algorytm dopasowywania wzorców : Nieznany sygnał mowy jest porównywany z referencyjnym wzorcem mowy w celu określenia rzeczywistych słów lub wzoru słów.
Działanie systemu
Zobaczmy teraz, jak właściwie działa cały system.

- Mowę można postrzegać jako falę akustyczną, tj. Sygnał przenoszący informacje o wiadomości. Normalny człowiek z ograniczoną szybkością ruchu swoich artykulatorów (narządów mowy) może wytwarzać mowę ze średnią szybkością 10 dźwięków na sekundę. Średnia szybkość informacji wynosi około 50-60 bitów / sekundę. Oznacza to, że w rzeczywistości wymagane jest tylko 50 bitów / sekundę informacji w sygnale mowy. Ta fala akustyczna jest przetwarzana przez mikrofon na analogowe sygnały elektryczne. Przetwornik analogowo-cyfrowy konwertuje ten sygnał analogowy na próbki cyfrowe, dokonując precyzyjnych pomiarów fali w dyskretnych odstępach czasu.
- Sygnał zdigitalizowany składa się ze strumienia okresowych sygnałów próbkowanych 16000 razy na sekundę i nie nadaje się do wykonywania rzeczywistych rozpoznawanie mowy proces, ponieważ wzór nie może być łatwo zlokalizowany. Aby wyodrębnić rzeczywistą informację, sygnał w dziedzinie czasu jest konwertowany na sygnał w dziedzinie częstotliwości. Odbywa się to za pomocą cyfrowego procesora sygnałowego przy użyciu techniki FFT. W sygnale cyfrowym składnik co 1/100thsekundy jest analizowany i obliczane jest widmo częstotliwości dla każdego takiego składnika. Innymi słowy, zdigitalizowany sygnał jest dzielony na małe części amplitud częstotliwości.
- Każdy segment lub wykres częstotliwości przedstawia różne dźwięki wydawane przez ludzi. Komputer dokonuje dopasowania nieznanych segmentów do zapisanej fonetyki danego języka. To dopasowanie wzorców odbywa się na 3 sposoby:
Stosowanie podejścia fonetycznego akustycznego : W podejściu fonetycznym akustycznym, generalnie używany jest ukryty model Markowa. Model ten rozwija niedeterministyczny model prawdopodobieństwa rozpoznawania mowy. Model ten składa się z dwóch zmiennych - ukrytych stanów fonemów zapisanych w pamięci komputera oraz widocznego segmentu częstotliwości sygnału cyfrowego. Każdy fonem ma swoje własne prawdopodobieństwo i segment jest dopasowywany do fonemu zgodnie z prawdopodobieństwem, a dopasowane fonemy są następnie zbierane razem w celu utworzenia poprawnych słów zgodnie z zapisanymi regułami gramatycznymi języka.
Korzystanie z metody rozpoznawania wzorców : W podejściu do rozpoznawania wzorców system jest szkolony za pomocą określonego wzorca mowy dla dowolnego języka, a nieznany wzorzec mowy jest porównywany z wzorcem referencyjnym mowy poprzez określenie odległości między sygnałami przy użyciu techniki dopasowania czasu.
Korzystanie ze sztucznej inteligencji : Podejście Sztucznej Inteligencji opiera się na wykorzystaniu podstawowych źródeł wiedzy, takich jak znajomość dźwięków wypowiadanych na podstawie pomiarów spektralnych, znajomość odpowiednich znaczących i syntaktycznych słów.
Czynniki, od których zależy system rozpoznawania mowy
System rozpoznawania mowy zależy od następujących czynników:
- Pojedyncze słowa : Musi być przerwa między kolejnymi wypowiadanymi słowami, ponieważ ciągłe słowa mogą się nakładać, utrudniając systemowi zrozumienie, kiedy zaczyna się lub kończy słowo. Dlatego między kolejnymi słowami musi panować cisza.
- Pojedynczy głośnik : Wielu mówców próbujących jednocześnie wprowadzić głos może powodować nakładanie się sygnałów i zakłócenia. Większość używanych systemów rozpoznawania mowy to systemy zależne od mówcy.
- Rozmiar słownictwa : Języki z dużym zasobem słownictwa są trudne do uwzględnienia przy dopasowywaniu wzorców niż języki z małym zasobem słownictwa, ponieważ szanse na pojawienie się niejednoznacznych słów są mniejsze w przypadku tych ostatnich.
System rozpoznawania mowy w systemie Windows 7
Chciałbym polecić następujące kroki każdej osobie używającej systemu rozpoznawania mowy Windows 7
- Otwórz Panel sterowania z menu Start lub klikając ikonę.
- Wybierz opcję Ułatwienia dostępu, a następnie kliknij opcję Rozpoznawanie mowy.
- Następnie kliknij ustaw mikrofon i wybierz mikrofon biurkowy z dostępnych opcji.
- Następnie przejdź do samouczka mowy i postępuj zgodnie z podanymi instrukcjami.
- Następnie wyszkol komputer pod kątem lepszych opcji, tak aby komputer przechował określony wzór sygnału mowy. W tym celu należy kliknąć opcję „Naucz komputer, aby lepiej Cię rozumiał”, a następnie postępować zgodnie z instrukcjami.
- Teraz uruchom ikonę rozpoznawania mowy i zacznij dyktować swoją mowę do komputera. Możesz także dodawać własne słowa do słownika komputerowego.
Praktyczne systemy rozpoznawania mowy: korzystanie z HM2007
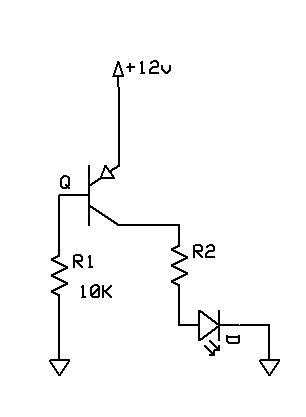
Praktyczny system rozpoznawania mowy można skonstruować za pomocą układu scalonego rozpoznawania mowy HM2007 . HM2007 to 48-pinowy układ scalony, który zapewnia funkcję rozpoznawania mowy. Działa w dwóch trybach: trybie ręcznym lub trybie procesora. W obu trybach układ scalony jest najpierw uczony rozpoznawania słów przez użytkownika wypowiadającego każde słowo dla odpowiadającej mu liczby naciśniętej na klawisz. Układ scalony przechowuje każdy sygnał słowa w komórce pamięci odpowiadającej temu słowu. Dane wyjściowe z układu scalonego są przekazywane do mikrokontrolera, skąd są wyświetlane na wyświetlaczu LCD.

Zwykle używamy trybu ręcznego do obsługi HM2007.
- HM2007 składa się z kołka RDY, który jest aktywnym pinem dolnym wskazującym, że układ scalony jest gotowy do celów szkoleniowych.
- Wejście głosowe będzie podawane przez mikrofon podłączony do styku MICIN układu scalonego.
- Układ scalony jest połączony z klawiaturą, która służy do wprowadzania liczb odpowiadających każdemu słowu. IC działa w dwóch funkcjach - Clear i Train. Po naciśnięciu klawisza Train na klawiaturze układ scalony rozpoczyna proces uczenia.
- Użytkownik naciska klawisz numeryczny przed naciśnięciem klawisza funkcyjnego „Train” i wypowiada wymagane słowo do mikrofonu.
- Układ scalony wysyła wysoki sygnał do pinu ME (włączanie pamięci), który jest podłączony do odpowiedniego pinu ME pamięci SRAM. 8-bitowy sygnał danych odpowiadający wciśniętej liczbie jest przechowywany w SRAM (zewnętrzna pamięć RAM) poprzez zewnętrzną magistralę.
- Po wykryciu wejścia głosowego pin RDY jest w stanie logicznym wysokim, a układ scalony przechodzi w stan rozpoznawania, w którym rozpoczyna proces rozpoznawania.
- Wynik procesu jest podawany przez magistralę danych z wysokim pinem DEN (Data Enable).
- 8-bitowe dane mogą być następnie przesłane do mikrokontrolera przez szeregowy procesor interfejsu lub najpierw zatrzaśnięte za pomocą zatrzasku IC 74HC573.
- Mikrokontroler jest połączony z wyświetlaczem LCD i jest zaprogramowany w taki sposób, że odpowiednie słowo jest wyświetlane na wyświetlaczu.
Jedyne środki ostrożności, jakie należy podjąć, to nie używać homonimów (słów o podobnym brzmieniu), a także zadbać o pobudzenie głosu.
Więc to wszystko, jak podstawowy system rozpoznawania mowy Pracuje. Wszelkie dalsze uwagi są mile widziane.
Źródło obrazu
Elementy systemu rozpoznawania mowy przez wprowadzenie do rozpoznawania mowy i rozpoznawania mówcy - Richard D. Peacocke i Daryl H. Graf







{kind=link}